Apache Spark is a cluster comuting framework for large-scale data processing, which aims to run programs in parallel across many nodes in a cluster of computers or virtual machines. It comibnes a stack of libraries including SQL and DataFrames, MLlib, GraphX, and Spark Streaming. Spark can run in four modes:
- The standalone local mode, where all Spark processes run within the same JVM process.
- The standalone cluster mode, which uses Spark’s own built-in, job-scheduling framework.
- Apache Mesos, where driver runs on the master node while work nodes run on separat machines.
- Hadoop YARN, where the underlying storage is HDFS. Driver runs inside an application master process which is managed by YARN on the cluster and work nodes run on different data nodes.
As Spark’s local mode is fully compatible with cluster modes, thus the local mode is very useful for prototyping, developing, debugging, and testing. Programs written and tested locally can be run on a cluster with just a few additional steps. In addition, the standalone mode can also be used in real-world scenarios to perform parallel computating across multiple cores on a single computer. In this post, I will walk through the stpes of setting up Spark in a standalone mode on Windows 10.
Table of Content
Installation
Install Java (7 or above)
Spark itslef is written in Scala, and runs on the Java Virtual Machine(JVM). Java has to be installed on the machines on which you are about to run Spark job.
Download Java JDK from the Oracle download page and keep track of where you installed it (e.g. C:\Program Files\Java\jdk1.8.0_161).
Set JAVA_HOME Variables
Set environmental variables:
- Varaiable: JAVA_HOME
- Value: C:\Program Files\Java\jdk1.8.0_161 (or your installation path)
Add %JAVA_HOME%\bin to PATH variable.
After the installation, you can run following command to check if Java is installed correctly:
java -version
If everything is fine, you will get similar response to the one below:
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
Install Spark
Download a pre-built version of Apache Spark from Spark Download page . The version I downloaded is 2.2.0, which is newest version avialable at the time of this post is written. You can download older version from the drop down list, but note that before 2.0.0, Spark was pre-built for Apache Hadoop 2.6. You might need to choose corresponding package type.
If neccessary, download and install WinRAR from http://www.rarlab.com/download.htm, so you can extract the .tgs file downloaded.
Extract Spark archive to C drive, such as C:\spark-2.2.0-bin-hadoop2.7.
Note: The folder name cannot have space!
Optional: open the C:\spark-2.2.0-bin-hadoop2.7\conf folder, and make sure “File Name Extensions” is checked in the “view” tab of Windows Explorer. Rename the log4j.properties.template to log4j.properties. Open the new file and change the error level from INFO to ERROR for log4j.rootCategory .
Set SPARK_HOME Variables
Set environmental variables:
- Varaiable: SPARK_HOME
- Value: C:\spark-2.2.0-bin-hadoop2.7 (or your installation path)
Add %SPARK_HOME%\bin to PATH variable.
Download Windows Utilities for Hadoop
Download winutils.exe file from https://github.com/stonefl/winutils/raw/master/hadoop-2.7.1/bin/winutils.exe and copy it into folder C:\hadoop-2.7.1\bin.
Note:
-
This is for a 64-bit system. If you are on a 32-bit version of Windows, you will need to search for a 32-bit build of winutils.exe for Hadoop.
-
If you are using Spark versions that is lower than 2.0, for example
spark-1.6.1-bin-hadoop2.6, you will need the winutils.exe for hadoop-2.6.0, which can be downloaded from https://github.com/stonefl/winutils/raw/master/hadoop-2.6.0/bin/winutils.exe
Set HADOOP_HOME Variables
Set environmental variables:
- Varaiable: HADOOP_HOME
- Value: C:\hadoop-2.7.1 (or your installation path)
Add %HADOOP_HOME%\bin to PATH variable.
Now, you can run spark-shell in the cmd(run as administrator) or PowerShell (run as administrator) to test the installation. If you can see the scala console shown as below, then you are good to go, Congratulations!
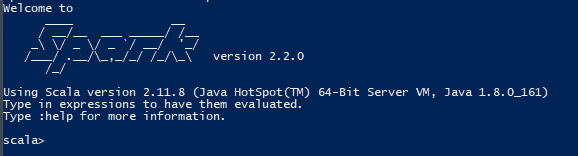
But it is very likely that you will get one or more following errors.
Common Errors
Common Error 1
<console>:16: error: not found: value sqlContext
import sqlContext.implicits._
^
<console>:16: error: not found: value sqlContext
import sqlContext.sql
^
All the commands must be executed in a command-line (cmd) or Powershell which run as Administrator, i.e. using Run as administrator option.
Common Error 2
The root scratch dir: /tmp/hive on HDFS should be writable. Current permissions are: rw-rw-rw-
First, make sure you are using correct winutils for your OS, as described above.
Second, check your computer domain through running C:\hadoop-2.7.1\bin\winutils.exe ls -F C:\tmp\hivein cmd or PowerShell with Run as administrator option. If this command returns access denied or FindFileOwnerAndPermission error, it means that your computer domain controller is not reachable, possible reason could be you are not one the same VPN as your system domain controller. Connect to your VPN and try again.
Finally, run following command, again in cmd or PowerShell with Run as administrator option, to grant access permission:C:\hadoop-2.7.1\bin\winutils.exe chmod -R 777 C:\tmp\hive
Common Error 3
When stop spark context, following error might pops up:
ERROR ShutdownHookManager: Exception while deleting Spark temp dir: C:\Users\MyUserName\AppData\Local\Temp\spark-76bd7db7-25fa-4096-8aa9-4e8dc02fcb67
java.io.IOException: Failed to delete: C:\Users\MyUserName\AppData\Local\Temp\spark-76bd7db7-25fa-4096-8aa9-4e8dc02fcb67
...
currently, I just ignore the error, since it seems no work around approach. I just keep deleting the temporary files from time to time. Please refer to following posts for more details on this issue and let me know if you find any solution to it.
https://stackoverflow.com/questions/30093676/apache-spark-does-not-delete-temporary-directories
https://issues.apache.org/jira/browse/SPARK-7439
References
Learning Spark O’Reilly http://shop.oreilly.com/product/0636920028512.do
http://nishutayaltech.blogspot.com/2015/04/how-to-run-apache-spark-on-windows7-in.html